


Définition de la reconnaissance d’images
La première question que vous pourriez vous poser est de savoir quelle est la différence entre la vision par ordinateur et la reconnaissance d’images. En réalité, la vision par ordinateur a été largement créée par Google, Amazon et de nombreux développeurs d’intelligence artificielle et les deux mots « vision par ordinateur » et « reconnaissance d’images » pourraient être utilisés de manière interchangeable. La vision par ordinateur (VA) permet à l’ordinateur d’imiter la vision et les performances humaines. Par exemple, la CV peut être programmée pour reconnaître un enfant qui court sur la route et envoyer un signal d’alerte au conducteur. La reconnaissance d’images, quant à elle, est le processus d’analyse des pixels et des formes d’une image pour l’identifier comme un objet spécifique. La vision par ordinateur implique qu’elle est capable de « faire quelque chose » à partir des images qu’elle reconnaît.
Qu’est-ce que la reconnaissance d’images exactement ?
Comme le dit le dicton, « Ce que vous voyez est ce que vous obtenez », le cerveau humain aide à voir. Faire la distinction entre un chien, un animal ou une soucoupe volante ne demande pas beaucoup d’efforts. Cependant, il est difficile pour les ordinateurs d’imiter ce phénomène : il semble facile en raison du fait que notre cerveau est extrêmement doué pour comprendre les images. Un exemple de reconnaissance par l’image est appelé reconnaissance optique de caractères (OCR). Le scanner est capable de reconnaître les caractères dans l’image et de transformer le texte d’une image en fichier texte. En utilisant le même processus, l’OCR peut être utilisé pour lire les mots des plaques d’immatriculation sur une image.
Quel est le processus de reconnaissance d’image ?
Comment apprend-on à un ordinateur à différencier différentes images les unes des autres ? Le processus de création d’un modèle de reconnaissance d’image n’est pas différent du processus utilisé dans la modélisation de l’apprentissage automatique. Nous allons décrire le processus de modélisation pour la reconnaissance d’images dans les étapes 1 à 4.
Modélisation Étape 1 : Extraire les caractéristiques des pixels d’une image
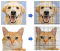
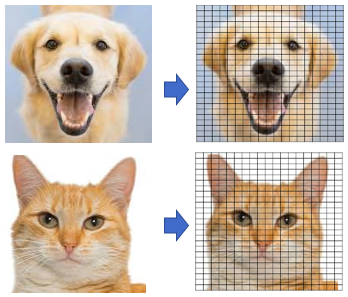
Figure (A)Tout d’abord, un certain nombre de traits, ou caractéristiques, sont extraits de l’image. L’image est composée de « pixels », comme le montre la figure (A). Chaque pixel peut être représenté par un nombre individuel ou un ensemble de nombres. Le nombre de nombres est appelé profondeur de couleur (ou profondeur binaire). En d’autres termes, la profondeur de couleur identifie le plus grand nombre de couleurs qui peuvent être utilisées dans une image. Dans le cas d’une image en niveaux de gris (noir et blanc) (8 bits), chaque pixel a une valeur comprise entre zéro et 255. La plupart des images modernes utilisent des couleurs de 24 bits ou plus. Une image en couleurs RVB indique que la teinte d’un pixel est le résultat de la combinaison du vert, du rouge et du bleu. Chaque couleur a une valeur comprise entre zéro et 255. Le générateur de couleurs RVB illustre comment chaque couleur peut être créée par RVB. Ainsi, un pixel a trois valeurs. RVB (102, 255 et 101) est la couleur #66ff66. Une photo de 800 pixels de large et 600 pixels de haut, soit 800 600 x 480, équivaut à 480 000 pixels. Cela représente 0,48 mégapixels (« mégapixel » correspond à 1 million de pixels). Une image d’une résolution de 1024×768 est une grille qui comporte 1 024 lignes et 768 colonnes. Elle est donc de 1 024 x 7,68, soit 0,78 mégapixels. Modélisation Étape 2 : préparer les images étiquetées pour créer le modèle 
Figure (B)
Après avoir converti chaque image en milliers de caractéristiques avec les étiquettes connues pour les photos, nous pouvons les utiliser pour créer des modèles. La figure (B) montre une variété d’images avec des étiquettes qui appartiennent à diverses catégories comme « chien » ou « poisson ». Plus nous pouvons choisir de photos pour chaque catégorie, plus le modèle sera capable de reconnaître une image, qu’il s’agisse d’une image de chien ou de poisson. Dans ce cas, nous savons à quelle catégorie appartient l’image et nous utilisons cette information pour apprendre au modèle. C’est ce qu’on appelle le processus d’apprentissage automatique supervisé.
Étape de modélisation 3 : Entraîner le modèle à catégoriser les images

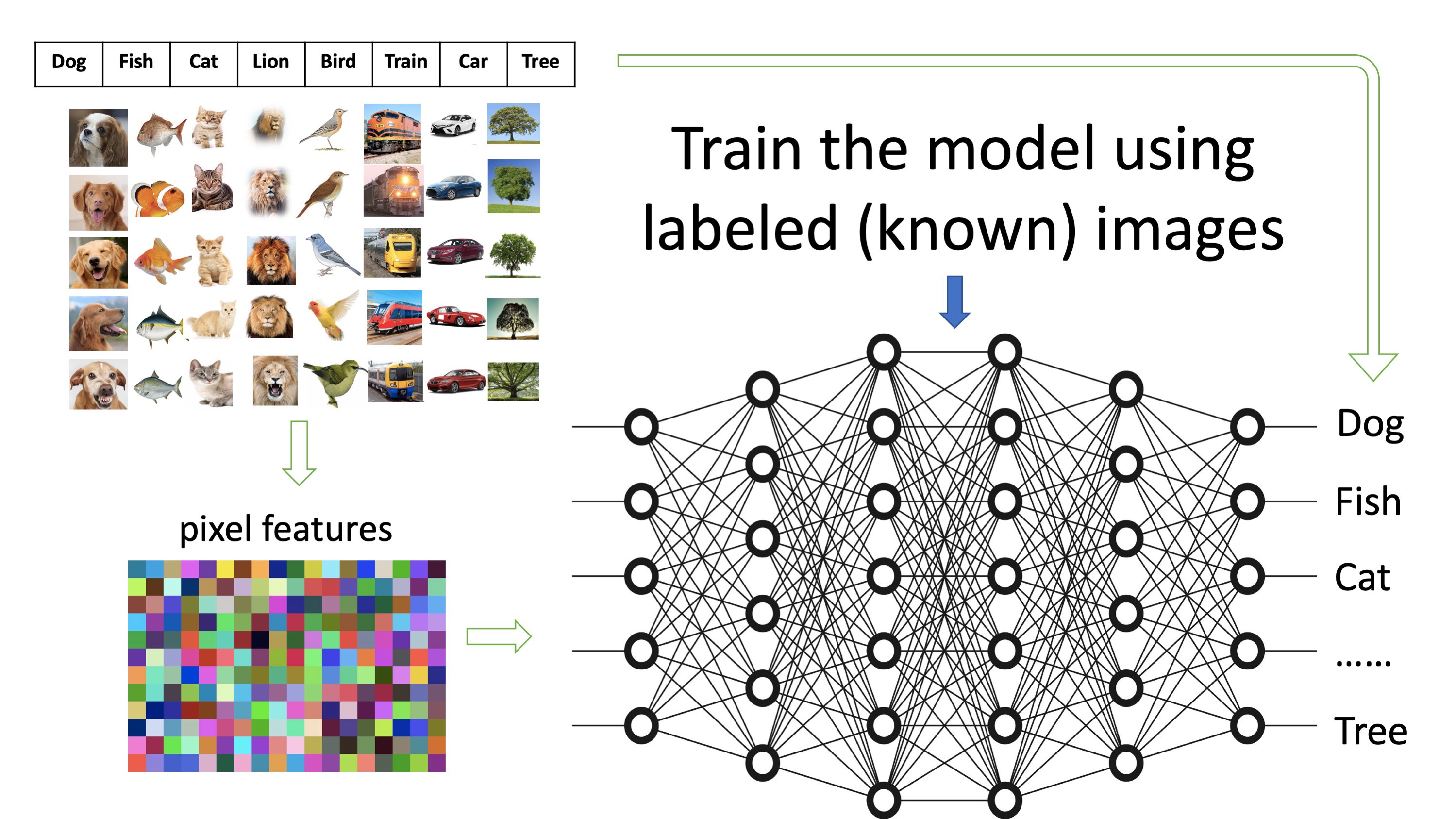
Figure (C)
La figure (C) illustre la manière dont un modèle est formé à l’aide des images qui ont été pré-étiquetées. Les vastes tableaux qui se trouvent au milieu peuvent être considérés comme un filtre massif. Les images avec leurs formes extraites se trouvent du côté de l’entrée tandis que les étiquettes sont placées du côté de la sortie. L’objectif est de développer les réseaux de manière à ce que l’image qui présente des caractéristiques en entrée corresponde à l’étiquette affichée à droite.
Étape 4 de la modélisation : reconnaître (ou prédire) qu’une toute nouvelle image entre dans les catégories.
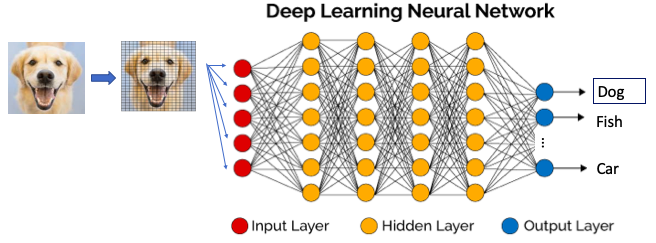
Une fois qu’un modèle a été développé, il est alors capable de détecter (ou d’anticiper) une image non identifiée. La figure (D) illustre comment la nouvelle image est identifiée comme étant une photo de chien. Il est important de noter que la toute nouvelle image va subir le processus d’extraction des caractéristiques des pixels.

Réseaux neuronaux à convolution – l’algorithme de reconnaissance d’image
Les graphiques représentés en (C) (C) ou (D) suggèrent que les modèles les plus utilisés sont les réseaux neuronaux. Les réseaux neuronaux à convolution (CNN ou ConvNets) sont largement utilisés dans le domaine des classificateurs d’images, de la détection d’objets ou de la reconnaissance d’images.
Une explication simple des réseaux neuronaux à convolution
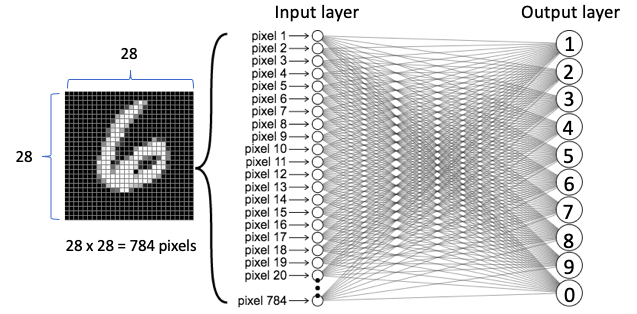
Je vais utiliser les chiffres de l’écriture manuscrite du MNIST pour aider à expliquer les CNNs. Ces images du MNIST sont des images noir et blanc de forme libre pour les chiffres de 0 à 9. Il est plus simple de comprendre le concept en utilisant des images en noir et blanc car chaque pixel ne représente qu’une seule valeur (0-255) (notez qu’une image en couleur a trois valeurs par pixel).
La couche qui est basée sur le réseau dans les CNN est distincte des réseaux neuronaux conventionnels. Il existe quatre types de couches, à savoir la convolution, les ReLU, la mise en commun et les couches entièrement connectées, comme l’illustre la figure (E). Que fait chacun de ces quatre types de couches ? Je vais vous l’expliquer.

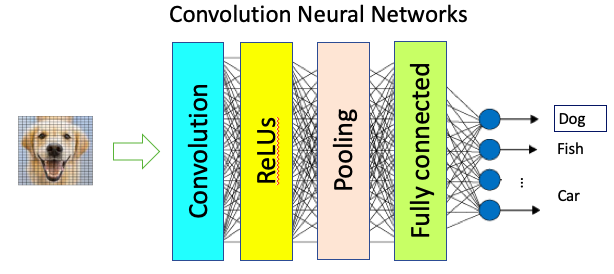
Couche de convolution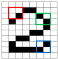
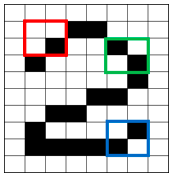
Figure (F)
La première étape que les CNNs accomplissent est de construire un certain nombre de petits morceaux appelés « caractéristiques » similaires à une boîte 2×2. Pour montrer ce processus, j’utilise trois couleurs différentes dans la figure (F). Chaque caractéristique représente une forme particulière dans l’image.
Permettez à chaque composant de scanner l’image originale. S’il y a une correspondance exacte, vous obtiendrez un score extrêmement élevé dans la boîte. Si la correspondance est faible ou inexistante, le score est nul ou faible. Cette méthode de génération de scores est connue sous le nom de filtrage.
 #
#
Figure (G)
La figure (G) illustre trois des caractéristiques. Chaque caractéristique crée une image qui est filtrée avec des scores élevés et faibles après que l’image originale ait été analysée. Par exemple, la case rouge a mis à jour quatre points de l’image originale qui coïncident complètement avec la caractéristique, d’où les scores élevés pour les quatre zones. Les cases roses représentent les zones qui correspondent d’une manière ou d’une autre. Le processus consistant à essayer toutes les correspondances possibles en analysant une image est appelé convolution. Les images qui ont été filtrées sont placées l’une sur l’autre pour former la couche de convolution.
2. Couche ReLUs
L’unité linéaire rectifiée (ReLU) est l’étape suivante, identique à celle des réseaux neuronaux normaux. Elle réduit toutes les valeurs négatives à zéro pour s’assurer que les mathématiques fonctionnent correctement.
3. Couche de mise en commun maximale.

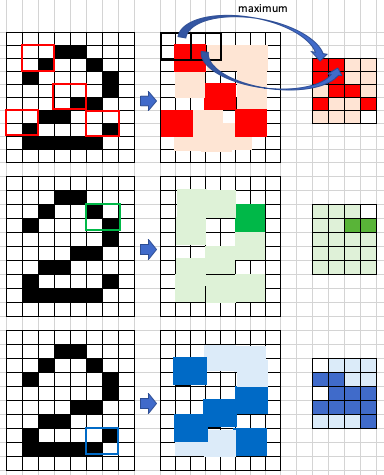 testFigure (H)
testFigure (H)
Le processus de mise en commun réduit la taille d’une image. Dans la figure (H), une image avec une fenêtre 2×2 analyse les deux images filtrées et attribue la valeur la plus élevée de la fenêtre 2×2 à une case 1×1 dans une image créée. Comme illustré dans l’image, la valeur la plus élevée de la fenêtre 2×2 initiale est le score le plus élevé (représenté par le rouge) et le score le plus élevé est attribué à la boîte. La boîte 2×2 se déplace vers la deuxième fenêtre, où il y a un score élevé (rouge) et un score faible (rose) et le score le plus élevé est attribué à 1×1. Après le processus de mise en commun, une nouvelle pile d’images plus petites qui ont été filtrées est produite.4. Couche qui est entièrement connectée (la dernière couche) 
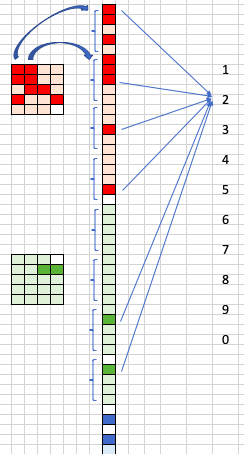
Nous séparons maintenant les images plus petites filtrées par taille et les mettons dans une liste comme illustré dans la figure (I). Chaque valeur de la liste prédit la probabilité de chacune des valeurs de 1,2,…, 0,1. Cette méthode est similaire à la couche de sortie utilisée dans les réseaux neuronaux standard. Dans notre cas, « 2 » reçoit le score le plus élevé parmi tous les nœuds de la liste. Les réseaux neuronaux peuvent donc reconnaître l’image manuscrite et l’interpréter comme « 2 ».
Quelle est la distinction entre les CNN et les réseaux neuronaux standard ?
Les réseaux neuronaux ordinaires combinent l’image originale pour créer une liste avant de transformer cette liste en une couche d’entrée. Les informations entre pixels voisins peuvent ne pas être sauvegardées. Cependant, les réseaux neuronaux construisent la couche de convolution qui préserve les informations partagées entre les pixels qui sont proches les uns des autres.

Avez-vous des codes CNN déjà créés que je pourrais utiliser ?
Oui. Si vous souhaitez vous familiariser avec l’algorithme, Keras propose plusieurs CNN préétablis, notamment Xception, VGG16, VGG19 ResNet50, InceptionV3, InceptionResNetV2, MobileNet, DenseNet, NASNet et MobileNetV2. La gigantesque base de données d’images ImageNet présente un intérêt particulier. Vous pouvez la télécharger ou y contribuer à des fins de recherche.
Applications commerciales
La reconnaissance d’images a une variété d’applications. Dans la prochaine section, je montrerai comment la reconnaissance d’images peut être utilisée pour faciliter les réclamations d’assurance.
Pour plus d’informations sur les définitions de la reconnaissance d’images :
reconnaissance d’images en python
reconnaissance d’images intelligence artificielle
reconnaissance d’images en ligne
reconnaissance d’images open source
logiciel gratuit de reconnaissance d’images
algorithme de reconnaissance d’images. algorithme de reconnaissance d’images

