


Qu’est-ce que Mapreduce ? Comment fonctionne-t-il ?
MapReduce est le moteur de traitement utilisé par Apache Hadoop, directement dérivé de MapReduce de Google. MapReduce est une application MapReduce est développée en Java. Elle vous permet de calculer facilement d’énormes quantités de données en appliquant des étapes de réduction et de mappage pour résoudre le problème sur le moment. Le processus de mappage prend un jeu de données existant et le convertit en un nouveau jeu de données en décomposant les éléments en paires clé/valeur appelées tuples. La deuxième étape de réduction utilise la sortie de la procédure de mappage et mélange les tuples de données pour créer des tuples plus petits.
MapReduce est un cadre de traitement parallèle haute performance qui peut être facilement mis à l’échelle sur d’énormes quantités de matériel courant pour répondre à la demande croissante de traitement de grandes quantités de données. Une fois que les tâches de réduction et de mappage sont en place, il suffit de modifier la configuration pour qu’elle fonctionne sur un ensemble de données plus important. Ce type d’échelle d’un nœud à des centaines, voire des milliers de nœuds, est la raison pour laquelle MapReduce est le favori des professionnels du Big Data dans le monde entier.
- Facilite le traitement parallèle nécessaire à l’exécution des tâches liées au Big Data.
- Convient à une gamme d’applications commerciales de traitement des données.
- Une option rentable pour les cadres de traitement central
- Il est possible d’intégrer SQL pour permettre l’utilisation du traitement parallèle.
L’architecture MapReduce
L’ensemble du processus MapReduce est une configuration de traitement extrêmement parallèle qui déplace le calcul vers l’emplacement des données, au lieu de déplacer les données vers l’emplacement du calcul. Ce type d’approche augmente la vitesse du processus, réduit la congestion du réseau et augmente l’efficacité de l’ensemble du processus.
L’ensemble du processus de calcul est divisé en trois étapes : le mappage, le brassage et la réduction.
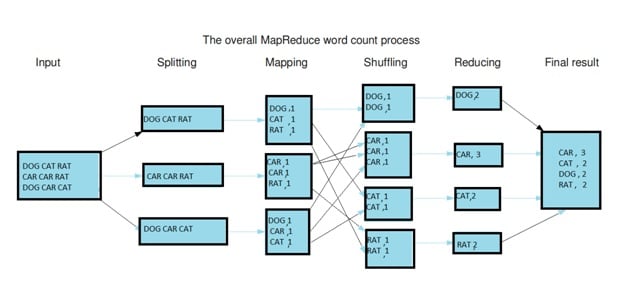
Étape de mappage L’étape de mappage est l’étape initiale de MapReduce. Elle implique la procédure de lecture des données à partir du système de fichiers distribués Hadoop (HDFS). Les données peuvent se présenter sous la forme de répertoires ou de fichiers. Le fichier de données qui est entré est transmis au mappeur, une ligne à la fois. Le mappeur traite les données et les décompose en blocs de données plus petits.
Phase de réduction La phase de réduction peut comporter plusieurs étapes. Pendant la procédure de brassage, les données passent du mappeur au réducteur. Sans le brassage des données, il n’y aurait pas de données à utiliser dans la phase de réduction. Toutefois, le processus de brassage peut commencer après l’achèvement du processus de mappage. Les données sont alors séparées afin de diminuer le temps nécessaire à la réduction de la quantité de données. Le tri peut aider au processus de réduction en donnant une indication que la clé suivante des données d’entrée qui ont été triées diffère de la clé précédente. Le processus de réduction nécessite une paire clé-valeur exacte pour la fonction de réduction qui utilise l’entrée clé-valeur. Le résultat du réducteur est directement utilisé pour le stockage dans le HDFS.
Voici quelques-uns des termes employés au cours du processus MapReduce :
- MasterNode C’est l’endroit où JobTracker fonctionne et accepte les travaux des clients.
- SlaveNode C’est l’endroit où les programmes de cartographie et de réduction sont exécutés.
- JobTracker est l’organisation qui planifie les travaux ainsi que le suivi des travaux qui sont assignés en utilisant Task Tracker.
- TaskTracker Le TaskTracker est l’entreprise qui gère réellement les tâches et donne le statut du rapport à JobTracker.
- Job MapReduce Le job MapReduce exécute le programme Mapper & Reducer sur un ensemble de données.
- Tâche : L’exécution du programme Mapper & Reducer sur un segment particulier de données.
- TaskAttempt – Une méthode pour compléter une tâche spécifique en utilisant le SlaveNode.
Quel est le problème que MapReduce tente de résoudre ?
MapReduce est un descendant direct de Google MapReduce qui était une technologie qui analysait de grandes quantités de pages Web pour produire des résultats contenant le terme recherché par l’utilisateur à l’aide de la boîte de recherche Google.
L’analyse d’énormes quantités de données était autrefois une tâche herculéenne. MapReduce simplifie le traitement des Big Data et les réduit en plus petits morceaux de données qui sont rapidement déployés pour n’importe quelle utilisation. Voici quelques-unes des caractéristiques distinctives de MapReduce :
Il est extrêmement simple de créer des applications MapReduce en utilisant le langage de programmation que vous préférez, comme Java, Python ou C++, ce qui en fait un choix populaire pour fonctionner sur des clusters Hadoop massifs. Il possède un haut niveau d’évolutivité et peut fonctionner sur des clusters Hadoop entiers, qui sont distribués sur du matériel commun. Il est hautement tolérant aux pannes et totalement infaillible. Même en cas de défaillance d’un nœud, ce qui est probable en raison de la nature matérielle du serveur, MapReduce peut fonctionner sans problème car les données stockées se trouvent à plusieurs endroits. Le calcul est déplacé dans la zone où se trouvent les données, ce qui est recommandé pour diminuer le temps nécessaire à l’entrée/sortie et améliorer la vitesse de traitement.
MapReduce offre un large éventail de capacités de traitement en parallèle. Il est utilisé par des entreprises avant-gardistes de tous les secteurs pour analyser des volumes massifs de données à une vitesse record. L’ensemble de la procédure est accessible par la mise en correspondance de fonctions et de réductions en utilisant du matériel bon marché pour atteindre un débit élevé. MapReduce est l’un des principaux éléments de l’écosystème Hadoop. Comprendre le fonctionnement de MapReduce peut vous donner un avantage lorsque vous postulez à des emplois dans le domaine d’Hadoop.
Quel est le public visé par cette technologie ?
- Les programmeurs Java et autres développeurs de logiciels
- Spécialistes, architectes et professionnels des tests de l’ordinateur central
- Professionnels des entrepôts de données et de l’analyse
- Comment ces connaissances peuvent-elles aider votre carrière ?
Le déploiement d’Hadoop est très répandu dans le monde d’aujourd’hui. MapReduce est l’un des moteurs de traitement les plus fréquemment utilisés dans Hadoop. Si vous maîtrisez cette technique, vous serez en mesure d’obtenir un salaire décent dans votre prochain emploi et de faire passer votre carrière à l’étape suivante.
Si vous comprenez les subtilités du travail avec le cluster Hadoop et que vous êtes capable de saisir les subtilités de l’architecture MasterNode, SlaveNode, JobTracker, TaskTracker et MapReduce, leurs interdépendances et la façon dont ils fonctionnent conjointement pour résoudre le problème des Big Data Hadoop, alors vous êtes bien placé pour occuper des postes bien rémunérés dans les meilleurs MNC du monde.
Quels sont les avantages de l’apprentissage de MapReduce ?
L’apprentissage de cette technologie présente de nombreux avantages. MapReduce est une méthode simple pour traiter des quantités massives de données. L’aspect le plus fascinant est que toute la procédure MapReduce est écrite en Java, un langage de programmation largement utilisé par les développeurs de logiciels. Cela peut être une aubaine pour faire progresser votre carrière, en vous permettant de passer d’un poste en Java à un poste en Hadoop et de vous faire remarquer.
Vous aurez un avantage lorsque vous travaillerez avec la plate-forme Hadoop si vous êtes capable d’écrire des programmes MapReduce. Certaines des plus grandes entreprises du monde utilisent Hadoop à une échelle qui n’a jamais été vue auparavant et l’avenir va s’améliorer pour ceux qui utilisent Hadoop. Des entreprises telles qu’Amazon, Facebook, Google, Microsoft, Yahoo, General Electric et IBM utilisent de grands clusters Hadoop pour analyser leurs énormes quantités de données. En tant que professionnel de l’informatique tourné vers l’avenir, cette technologie peut vous aider à battre vos concurrents et à élever votre carrière à un niveau supérieur.

